Introduction
In computer science, an LALR parser or Look-Ahead LR parser is a simplified version of a Canonical LR parser. It was invented by Frank DeRemer in his 1969 PhD. dissertation "Practical Translators for LR(k) languages" in order to address the practical difficulties of that time of implementing Canonical LR parsers. The simplification that takes place results in a parser with significantly reduced memory requirements but decreased language recognition power. However, this power is enough for many real computer languages including Java. Usually this happens with the addition of some hand-written code that extends the power of the parser.
LALR parsers are automatically generated by compiler compilers such as Yacc and GNU Bison.
As with other types of LR parser, an LALR parser is quite efficient at finding the single correct bottom-up parse in a single left-to-right scan over the input stream, because it doesn't need to use backtracking. Being a look-ahead parser by definition, it always uses a look-ahead, with LALR(1) being the most common case.
The LALR(1) parser uses production rules of the form:
As is the case with any parser based on the LR(1) parser. The simplification that the LALR parser introduces consists in merging rules that differ only in the look-ahead. This reduces the power of the parser because, as the following example depicts, dropping the look-ahead info can confuse the parser as to which grammar rule to pick next, resulting in a reduce/reduce conflict.
 In a LR(1) parser the state sequence is correctly resolved to A3, because the look-ahead information has been preserved through the detailed rule system. In a LALR parser the state sequence cannot be resolved because the parser encounters a duplicate rule, which is an error. The above grammar will be declared ambiguous by a LALR parser generator.
In a LR(1) parser the state sequence is correctly resolved to A3, because the look-ahead information has been preserved through the detailed rule system. In a LALR parser the state sequence cannot be resolved because the parser encounters a duplicate rule, which is an error. The above grammar will be declared ambiguous by a LALR parser generator.
Steps involve in LALR(1)
Steps which involve in converting LR(1) to LALR(1) are:
In computer science, an LALR parser or Look-Ahead LR parser is a simplified version of a Canonical LR parser. It was invented by Frank DeRemer in his 1969 PhD. dissertation "Practical Translators for LR(k) languages" in order to address the practical difficulties of that time of implementing Canonical LR parsers. The simplification that takes place results in a parser with significantly reduced memory requirements but decreased language recognition power. However, this power is enough for many real computer languages including Java. Usually this happens with the addition of some hand-written code that extends the power of the parser.
LALR parsers are automatically generated by compiler compilers such as Yacc and GNU Bison.
As with other types of LR parser, an LALR parser is quite efficient at finding the single correct bottom-up parse in a single left-to-right scan over the input stream, because it doesn't need to use backtracking. Being a look-ahead parser by definition, it always uses a look-ahead, with LALR(1) being the most common case.
The LALR(1) parser uses production rules of the form:

As is the case with any parser based on the LR(1) parser. The simplification that the LALR parser introduces consists in merging rules that differ only in the look-ahead. This reduces the power of the parser because, as the following example depicts, dropping the look-ahead info can confuse the parser as to which grammar rule to pick next, resulting in a reduce/reduce conflict.
- State sequence : A, B, C
- Current look-ahead: a
- Rules (LALR merge rules in brackets):

Steps involve in LALR(1)
Steps which involve in converting LR(1) to LALR(1) are:
- Context Free Grammar (CFG)
- Augmented CFG with follow sets
- DFA
- LR(1)
- Parse table of LR(1)
- Merge states of LR(1) – states with similar data
- Resultant is LALR(1)
- Parse table of LALR(1)
Context Free Grammar (CFG)

Augmented CFG with follow sets
 DFA – LR(1)
DFA – LR(1)
The DFA of LR(1) is
 Parse table LR(1)
Parse table LR(1)
 DFA - Merging states of LR(1)
DFA - Merging states of LR(1)
Merge S4 and S7
 After merging S4 and S7, the state will be S47 and DFA will be
After merging S4 and S7, the state will be S47 and DFA will be
 Now, merge S8 and S9
Now, merge S8 and S9
 After merging S8 and S9, the state will be S89 and DFA will be
After merging S8 and S9, the state will be S89 and DFA will be
 Now, merge S3 and S6
Now, merge S3 and S6
 After merging S3 and S6, the state will be S36 and DFA will be
After merging S3 and S6, the state will be S36 and DFA will be
 DFA – Resultant is LALR(1)
DFA – Resultant is LALR(1)
 Parse table of LALR(1)
Parse table of LALR(1)
Now, the parse table of LALR(1) is
 Execution of a string
Execution of a string
To test the LALR(1) DFA, we input a string and prove it according to its parse table. The input string is bdd$

Feel free to comment with your questions and suggestions regarding the post content...!

Augmented CFG with follow sets
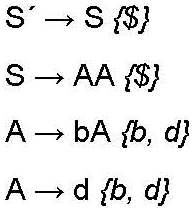
The DFA of LR(1) is


Merge S4 and S7







Now, the parse table of LALR(1) is

To test the LALR(1) DFA, we input a string and prove it according to its parse table. The input string is bdd$

Feel free to comment with your questions and suggestions regarding the post content...!
i searched LALR parser example for such a long time, but couldn't able to find such nice explanation with example...!!! Now my searching came to end...!!
ReplyDeleteCan you please tell how to apply reduction in Canonical LR(1). in Parse table of LR(1) at state 4 we have to apply reduction, confusion is where to go on S3 or S2? if u can help me please tomorrow is my grand test.
ReplyDelete